
Getting Started With Enterprise and Federated Search Integrations
- Applies to:
- CXone Mpower Expert (current)
Understanding enterprise and federated search
Enterprise Search addresses the need for easy access to information when the information is spread out across multiple locations in an enterprise-sized organization. Information is typically stored in different data sources such as websites, databases, and file systems. The primary approaches to provide Enterprise Search are querying federated search engines and building a centralized search index. Most leading Enterprise Search companies can provide both approaches.
Not every search technology company provides their services to enterprise-sized organizations, and therefore do not leverage the label “Enterprise Search”. In addition, Enterprise Search sometimes carries the preconception of “searching internal systems for internal use cases”, thus appearing to be incompatible with customer-facing self-service experiences. An example vendor who chooses not to rely exclusively on the "Enterprise Search" label is Coveo, who provides solutions for customer experience and customer support use cases.
Querying federated search engines
This is the recommended approach to provide a unified, multiple data source, search experience that includes an Expert site data source.
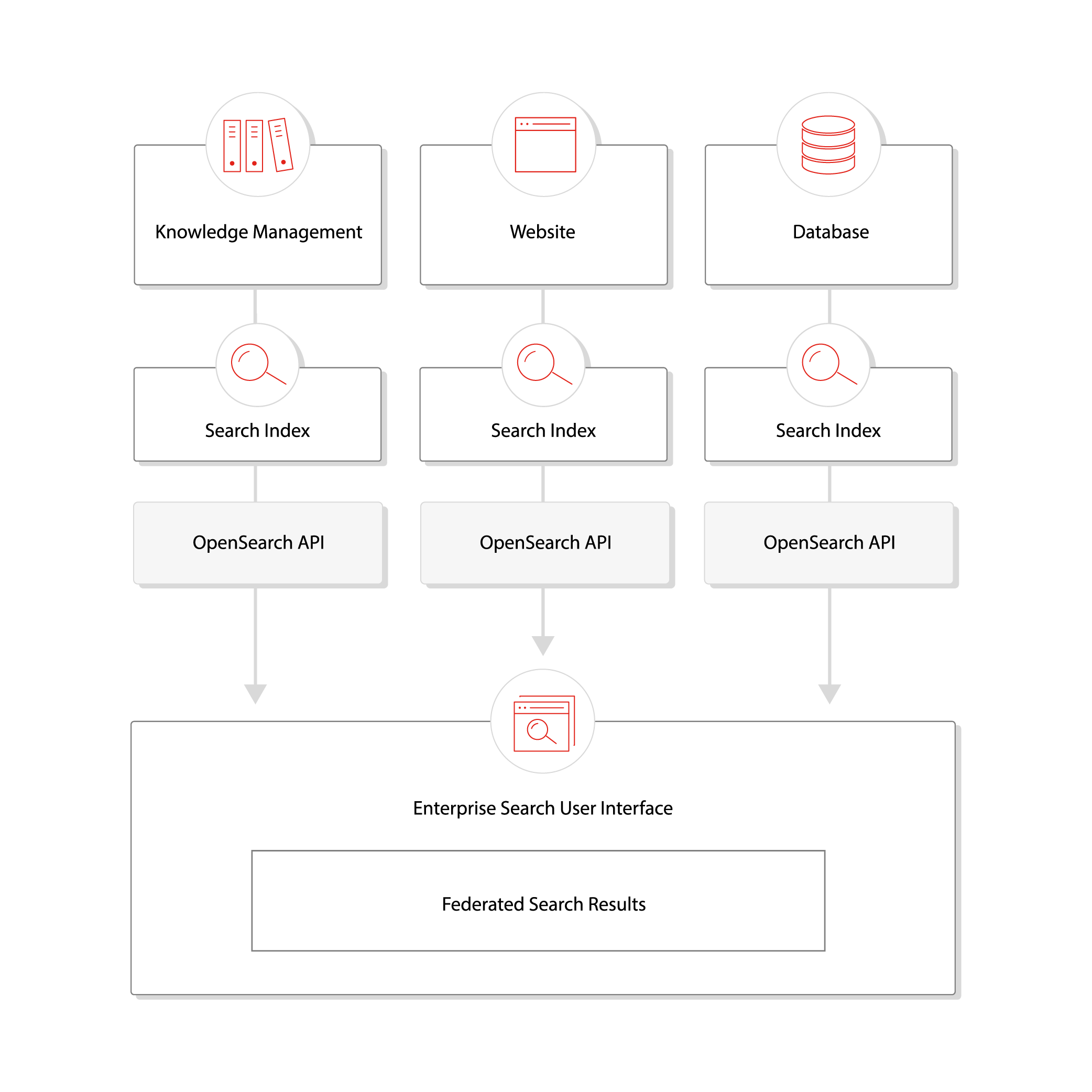 Querying federated search engines (called “federated search”) is the practice of providing a unified search experience that, behind the scenes, queries the search indexes of multiple data sources and presents the collected results. This approach takes advantage of any search indexing or querying optimizations that the data sources have developed, such as natural language processing, to provide the most relevant data or knowledge. Often it is best to let a data source handle the indexing of its own data as the developers of the data source understand how the information should be organized and fetched.
Querying federated search engines (called “federated search”) is the practice of providing a unified search experience that, behind the scenes, queries the search indexes of multiple data sources and presents the collected results. This approach takes advantage of any search indexing or querying optimizations that the data sources have developed, such as natural language processing, to provide the most relevant data or knowledge. Often it is best to let a data source handle the indexing of its own data as the developers of the data source understand how the information should be organized and fetched.
Benefits
-
Available information is always fresh and up-to-date. There is no need to periodically crawl data sources: they are responsible for crawling or indexing their own data
-
The Industry-standard OpenSearch API is a universal standard for federated search queries, allowing for wider compatibility among data sources and search vendors and reducing time to implement. Expert supports the latest version of the OpenSearch API specification. Results from the Expert OpenSearch API endpoint are RSS and Atom compatible
Drawbacks
-
Synchronizing content permissions, if necessary, between a unified search experience and multiple data sources, can be challenging. If all data sources support a common authorization protocol, such as OAuth 2.0, the complexity is decreased. For permission-controlled OpenSearch API access, Expert supports authorization via Server and OAuth API token
-
Data source specific user experiences and content types may not translate to the OpenSearch specification. Expert’s search filtering, faceting, and insights tracking are implemented with proprietary APIs, not OpenSearch. A unified search user interface, unless an Expert-specific connector is developed, would unlikely be able to filter, facet, or track search insights in the same manner as Expert's built-in search interface
Unified search experiences, that leverage the federated search approach, are typically designed to provide a homogeneous user interface, regardless of which data sources are integrated. Expert filtering or faceting options may be unavailable in the user interface.
Building a centralized search index
Crawling data sources and attempting to control the end-to-end experience can reduce the value of a smart knowledge management solution. When considering a centralized search index, evaluate which data sources are appropriate to include in the centralized search index, and which data sources, like Expert, provide more value through a federated search integration.
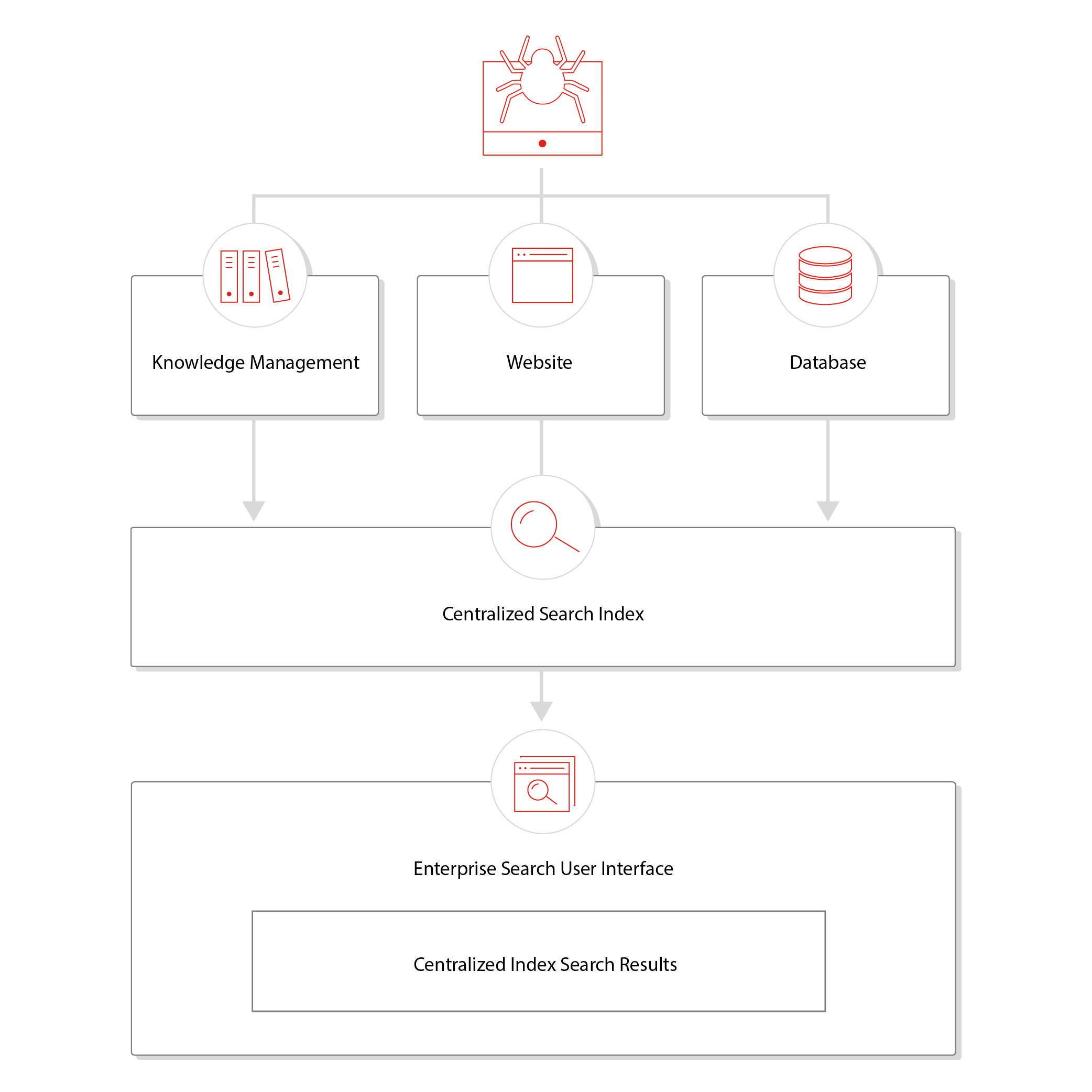
Content crawling and indexing is the practice of deploying a crawler to discover and fetch data from an organization's multiple websites, databases, and file systems to store in a single, centralized search index. The centralized search index provides results for a unified search experience.
The crawler is responsible for keeping data fresh and up-to-date in the centralized search index. The search engine provides the necessary algorithms and query languages necessary to connect users with the relevant content in the centralized search index. A sitemap is particularly useful to crawlers as it helps them discover and traverse complex information architectures.
Benefits
- Crawlers can index data sources that normally would not be searchable. Data sources, such as websites, that do not index data or provide an API for querying can be crawled to collect information
- A centralized search index provides complete end-to-end control of the unified search experience. This is important if data sources' native search indexing or querying capabilities do not meet the needs of customers or users
Drawbacks
- Native access control functionality of the data source may not be available after crawling content
- No benefit from any optimizations or insight that is provided when querying data sources' search indexes. If a data source can leverage historical or behavioral data to provide the most relevant results from the data source, that optimization will not be available to a crawler when it is indexing the data source
- Keeping content fresh and up-to-date can be very challenging. If data sources do not have reliable sitemaps, RSS/Atom feeds, or a standard way of communicating that a document has been updated, the integration between the search engine and the data source relies on either:
- Crawling the entire data source at a regular cadence to determine if one or more pieces of information have been created or updated since the last crawl
- Querying a proprietary data source API to check periodically for updates
Since crawling can be a high web-traffic activity, there may be limitations imposed by the data source to control how often the data source can be crawled for changes. Without limitations, and with a frequent crawling cadence, operational costs for both the crawler and data source will be unnecessarily high. Aggressive crawlers can also trigger Denial of Service protection systems, which protect data sources from volume-based attacks and have other negative operational impacts.